Persistance avec JPA
JPA pour Java Persistance API est la spécification ORM de la plateforme JavaEE. Un ORM, pour Object Relationnal Mapper, est un composant logiciel chargé de faire le lien entre le modèle objet et le modèle relationnel et permet ainsi de persister des classes Java dans une système de gestion de base de donnée relationnel sans écrire tout le code JDBC directement. Le moteur vas ainsi établir et exécuter les opérations JDBC nécéssaires. JPA étant une spécification, on a besoin de choisir une implémentation pour l'utiliser. Nous allons utiliser la plus connue, Hibernate, mais il en existe d'autres, comme EclipseLink, TopLink, etc ...
Dépendances
Pour utiliser JPA avec Hibernate, il faut rajouter ces dépendances à notre projet :
<dependency>
<groupId>jakarta.persistence</groupId>
<artifactId>jakarta.persistence-api</artifactId>
<version>2.2.3</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>5.4.22.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>5.4.22.Final</version>
</dependency>
Data Source
Pour pouvoir accèder à une base donnée avec JPA, il faut configurer une Datasource sur notre serveur d'application. Pour cela, nous allons devoir accèder à l'interface d'administration de notre serveur Wilfly.
Créer un utilisateur d'Administration sur Wildfly
Rendez vous dans WILDFLY_HOME/bin et exécutez :
./add-user.bat
Suivez ensuite les instruction pour créér un utilisateur. Lorsqu'on l'on vous demande le type d'utilisateur choisissez Utilisateur d'administration.
Vous pouvez ensuite accèder au panneau d'administration Wildfly via ce lien (Le serveur Wildfly doit être démarré). Les identifiants pour se connecter sont ceux donnés à la création de l'utilisateur.
Configurer le Driver
Commencez par télécharger le Driver JDBC MySQL sur ce lien, décompressez le et récupérez le fichier JAR.
Ouvrez maintenant l'interface d'administration à http://localhost:9990 et rendez vous dans l'onglet Deployement. Ajoutez ensuite un nouveau déploiement en cliquant sur le bouton + puis Upload Deployment:
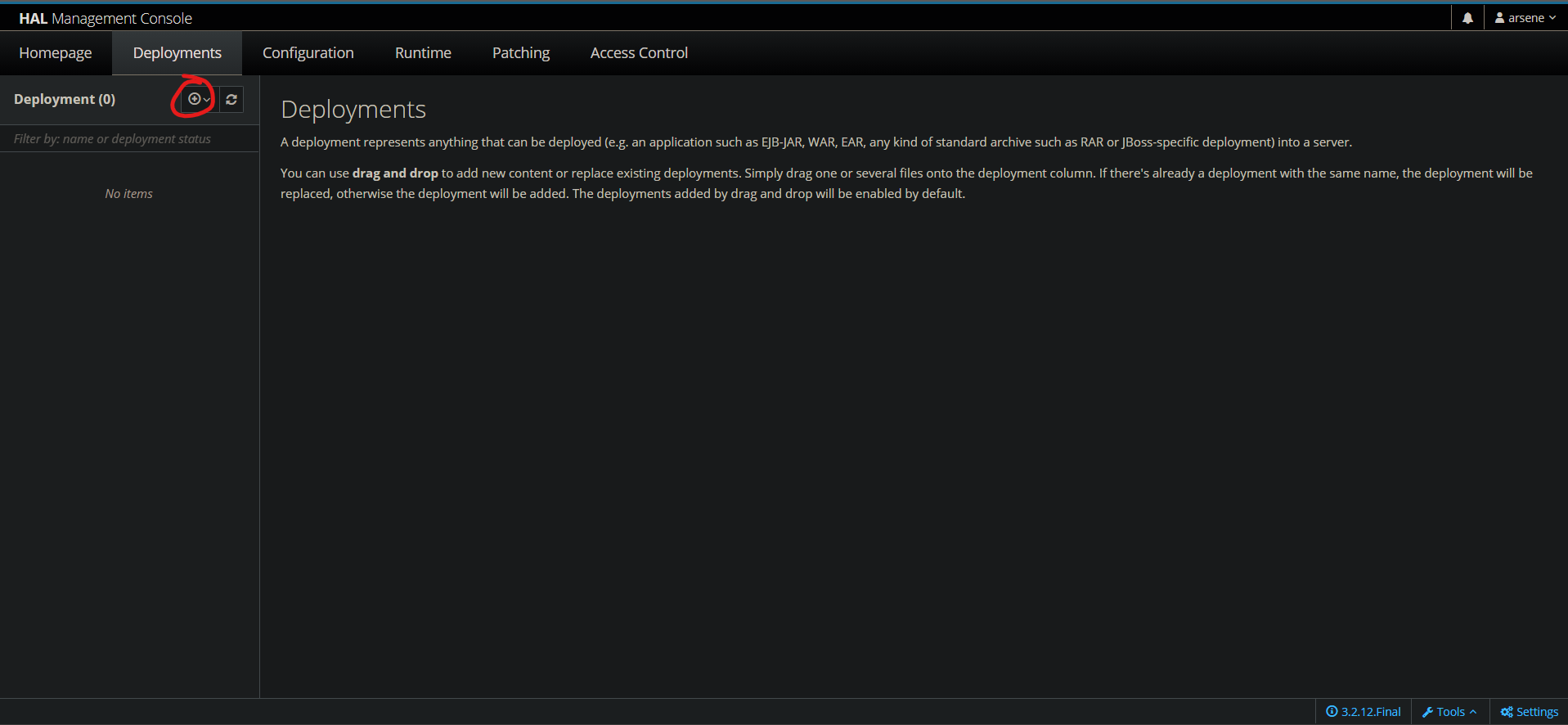
Dans la fenêtre qui s'ouvre, uploadez votre JAR JDBC et validez. Si tout ce passe bien il devrait être répertorié ici dans les déploiements :
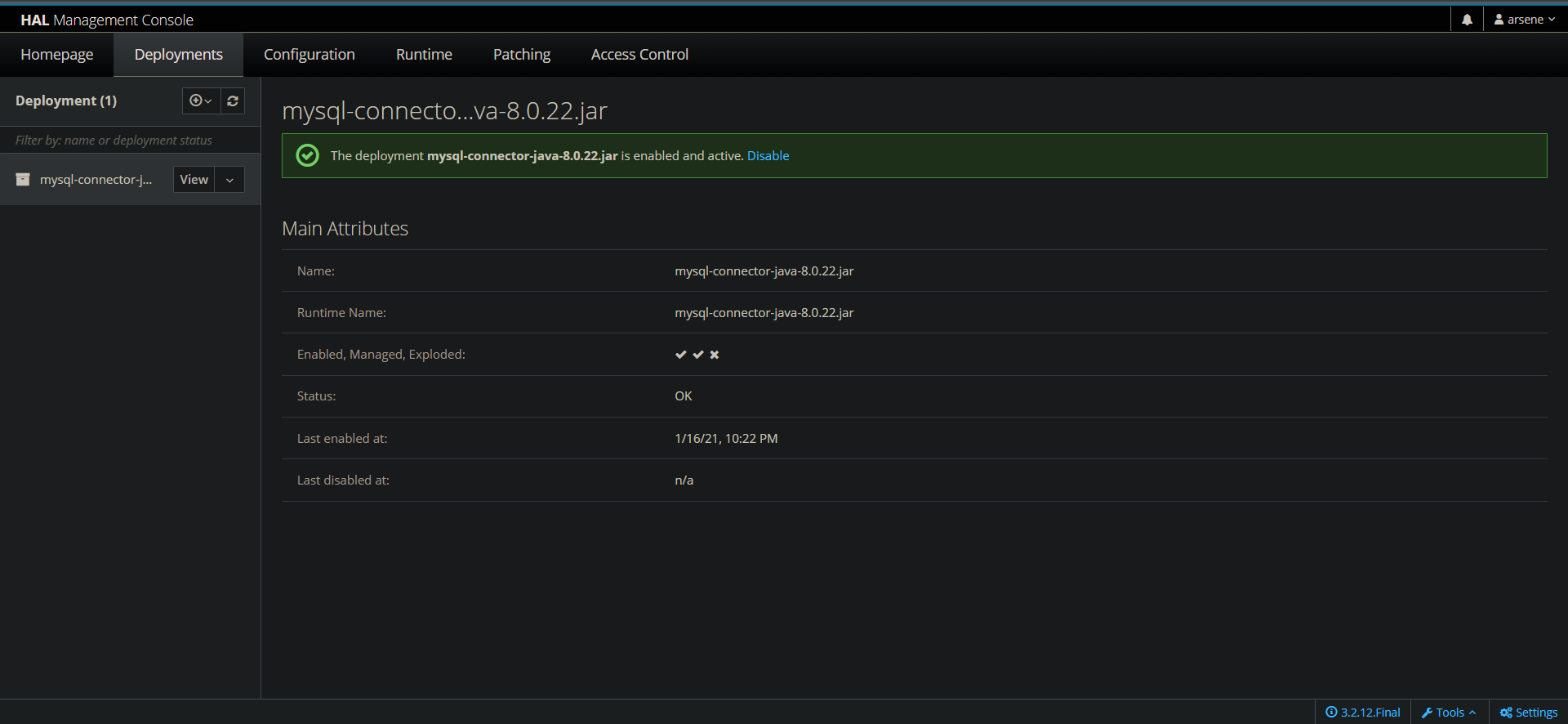
Ainsi qu'ici dans l'onglet Configuration sous Configuration -> Subsystems -> Datasources & Drivers -> JDBC Drivers.
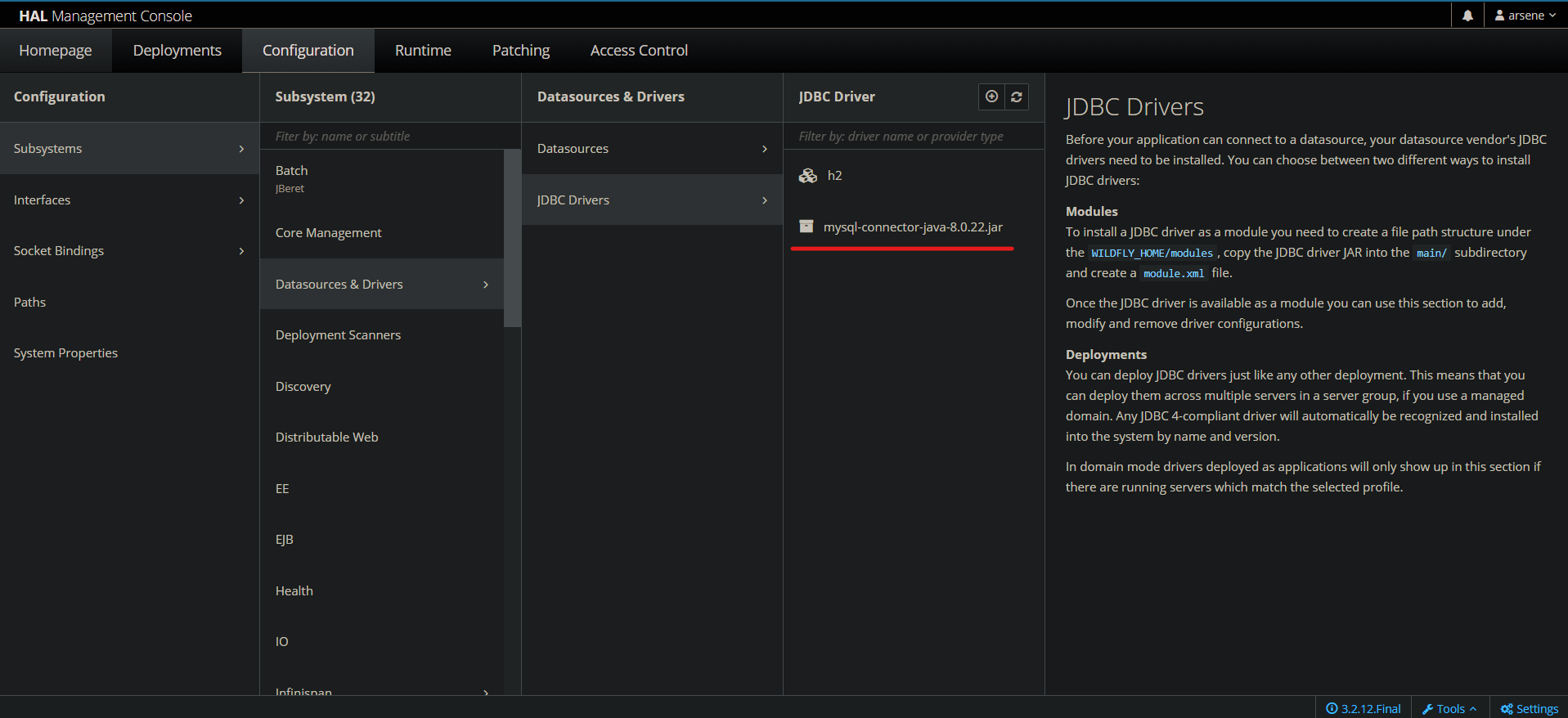
Configurez la source de donnée
Sur l'interface d'administration de Wildfly, allez à Configuration -> Subsystems -> Datasources & Drivers -> Datasources et utilisez le boutons + et New Datasource. Suivez ensuite les instructions du wizard en renseignant les informations.
Choisir notre SGBD :
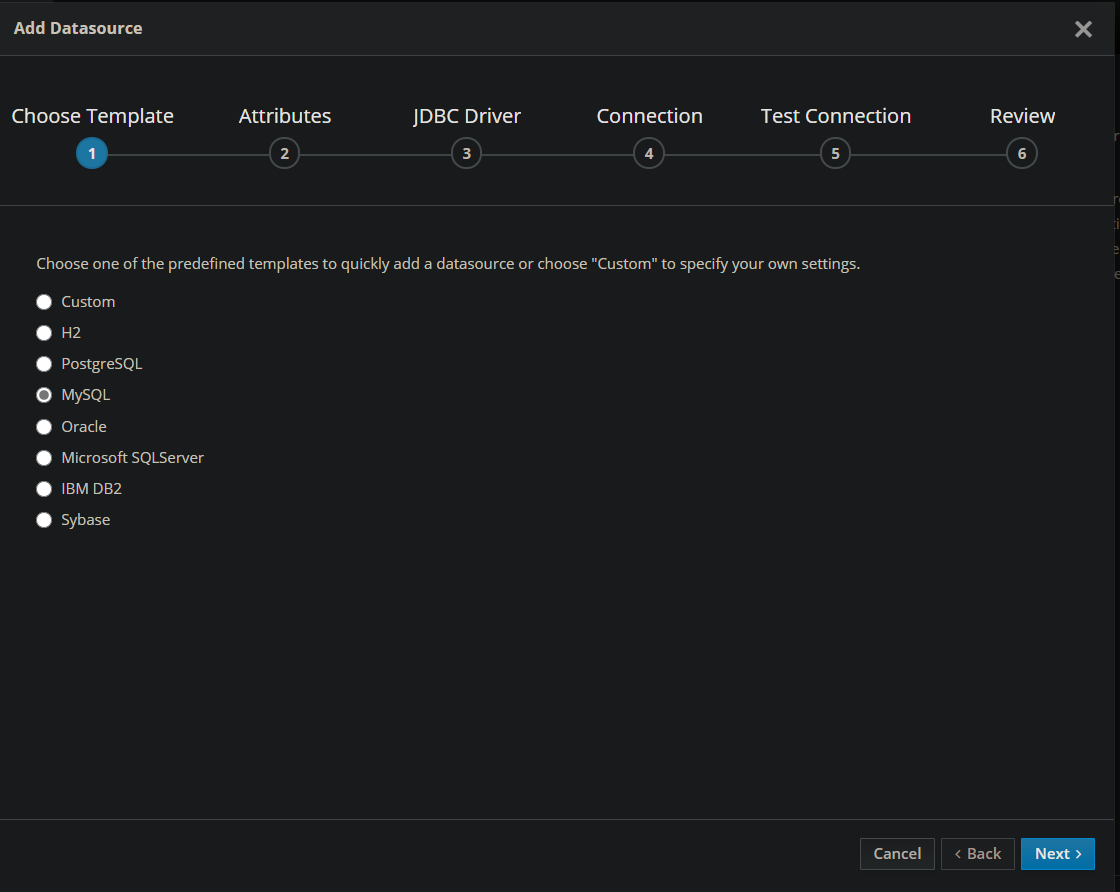
Dans attributes, vous pouvez choisir un nom pour votre Datasource ainsi que son adresse dans l'annuaire JNDI.
Choisir le driver que nous avons déployé :
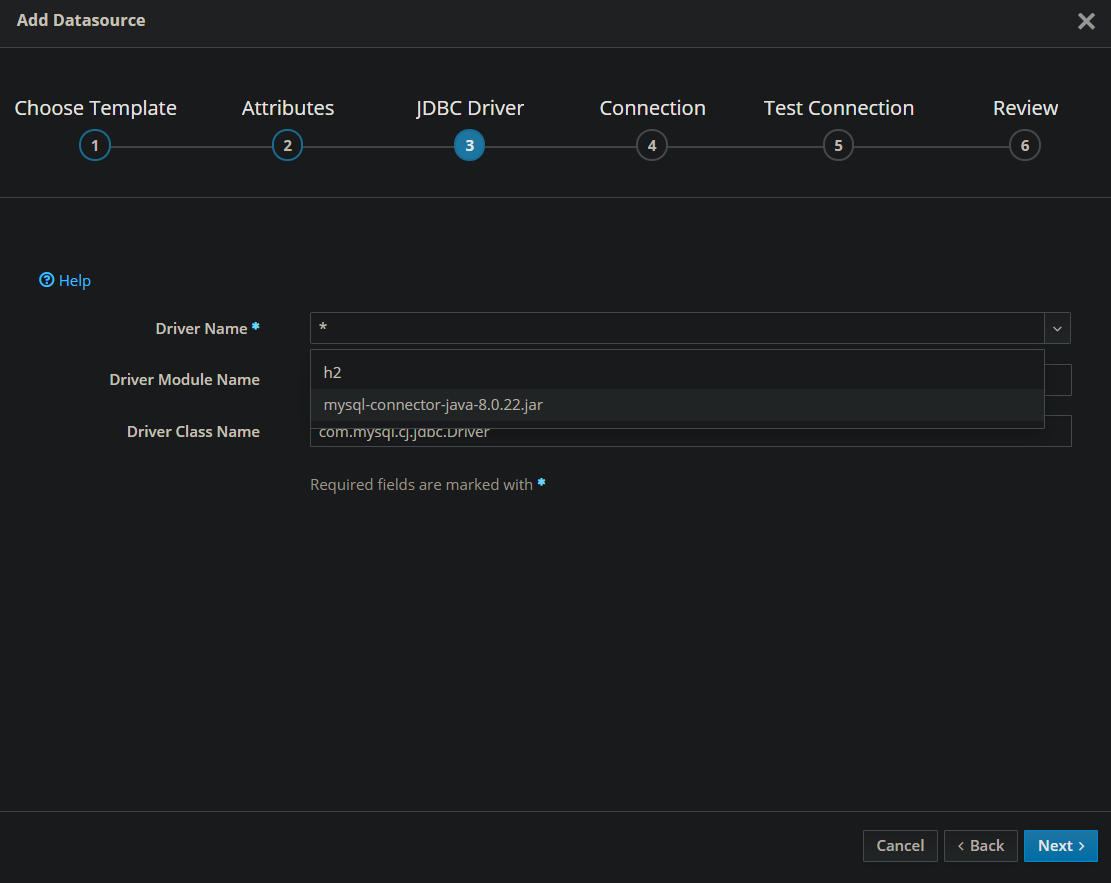
Pour les identifiants de votre base de donnée voici comment les renseigner :
- URL :
jdbc:mysql://localhost:3306/<nom de la base> - Username : votre login mysql
- Password : votre mot de passe mysql
Vous pouvez utiliser le bouton Test Connection pour vérifier que les information son correctes.
Il m'est déjà arrivé que le bouton Test Connection ne marche pas mais que la datasource soit tout de même bien configurée et fonctionnelle
Utiliser le nouvelle source de donnée
Dans votre projet, sous le dossier resources, créez un dossier, META-INF et dans ce dernier un fichier, persistence.xml, et entrer ce contenu pour référencer votre datasource dans votre projet :
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd"
version="2.2">
<persistence-unit name="default">
<jta-data-source>java:/MySqlDS</jta-data-source>
<properties>
<property name="hibernate.hbm2ddl.auto" value="update"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.MariaDBDialect"/>
</properties>
</persistence-unit>
</persistence>
Voilà, votre datasource est configurée, nous allons pouvoir maintenant étudier plus en détail les outils proposés par JPA.
EJB Entity
Les EJB Entity sont des EJB particuliers qui servent à représenter des données. Pour créer un EJB entité, il faut créer une classe annotée avec l'annotation @Entity. Une classe entité doit avoir un attribut annoté avec @Id qui correspondra à la clé primaire dans la table de la base de donnée. Chaque propriété de l'entité sera mappée à la colonne de la base de donnée.
Les autres champs de la classe entités sont persistés automatiquement. Pour qu'un champs ne soit pas persisté, il faut l'annoter avec @Transient.
Exemple d'entité :
@Entity
public class Todo {
@Id
@GeneratedValue(generator = "uuid")
@GenericGenerator(name = "uuid", strategy = "uuid2")
private String id;
private String title;
private String description;
... getters & setters ...
}
Ici l'annotation @GeneratedValue(strategy= GenerationType.AUTO) permet de générer automatiquement l'id avec un auto-incrément.
On peut aussi définir des contraintes sur les colonnes en rajoutant l'annotation @Column sur le champs et en lui passant des paramètres, par exemple :
@Column(unique = true, length = 32)
Cela permet de mettre la contraint "unique" sur le champs et d'imposer une longueur maximum de 32 caractère